Building with AWS OpenSearch Serverless
Posted on January 10, 2023 • 7 minutes • 1279 words
Table of contents
AWS has had a search product offering for several years, previously called Elasticsearch. OpenSearch is a fork of Elasticsearch and Kibana . The Amazon OpenSearch Service is a managed service that runs OpenSearch, where the installation, patching and replication is managed for the customers.
Recently Amazon OpenSearch Serverless was announced that allows the use of the same service but will automatically scale and where you pay for the resources consumed, this is split over the cost of Compute and cost of Storage.
Amazon states that:
…you can use OpenSearch Serverless to run petabyte-scale workloads without configuring, managing, and scaling OpenSearch clusters.
I decided to explore this new service whilst it was in preview, and I did find out some interesting things.
Cost
Amazon call one compute unit a OpenSearch Compute Unit (OCU) , this correlates to 6GB of RAM, “corresponding” vCPU, storage and S3 data transfer costs. This is split down further to Indexing and Searching, billed on an hourly basis but with per-second granularity. Data that is persisted on S3 is billed by gigabytes per month.
The minimum bill is for 4 OCUs broken down to 2x Indexing OCUs and 2x Search OCUs. This minimum is on the first collection in an account but other collections can share these 4 OCUs.
I have to admit, I didn’t initially find this pricing very clear, and also it didn’t feel very “serverless” - as I would like to see a scale-to-zero model and naively that is what I thought this product would be. Running a Search cluster has never been cheap for the smaller hobby style projects - so does this make it more affordable?
The costs are currently $0.24 per OCU per hour. Storage is $0.024 per GB per month. Therefore running the minimum 4 OCUs will be about $700 a month for OCUs alone, and this is even if no searching or indexing occurs.
Comparing that to the traditional approach, a cluster of three t3.small.search instances would cost about $80, or $57 if including the free tier in the calculations. Therefore serverless is much worse when looking at cost alone for a small search cluster. For a large cluster though, provisioning r6g.xlarge.search instances across multiple availability zones with enough power to handle spikes could very easily go over $1500 - so if the traffic is spiky then a serverless offering that grows and shrinks could save a lot.
Carl Meadows, who leads the Product Management team for Amazon OpenSearch Service commented on the announcement blog about cost:
As we go forward to GA and beyond we will look at additional options to help lower the entry point and drive greater cost efficiency like pause and reduce on indexing and search when there are no requests coming in etc.
Until that comes to fruition then serverless looks to only make sense for those with the larger use-cases, and for hobby projects then a traditional managed search cluster is better. I was surprised coming into this blind but after reading the provided material then I can see where this fits in the market, as the cost of managing a large cluster is much higher than a smaller one - so this is hitting that market sector.
Scalability
The scalability is the main draw of the Serverless offering, in that it allows less up-front configuration and AWS will manage the clusters for you. A maximum OCU can be configured in the account to control costs, but ultimately the premise is that you don’t need to worry about it once it’s setup and configured.
Let’s Build
I built a project in CDK that can be found on GitHub if you want to see the detail and try yourself: https://github.com/makit/aws-opensearch-serverless
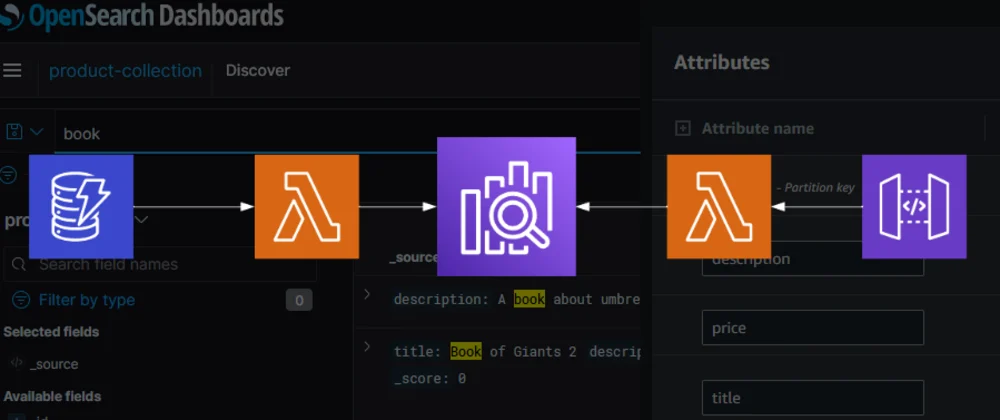
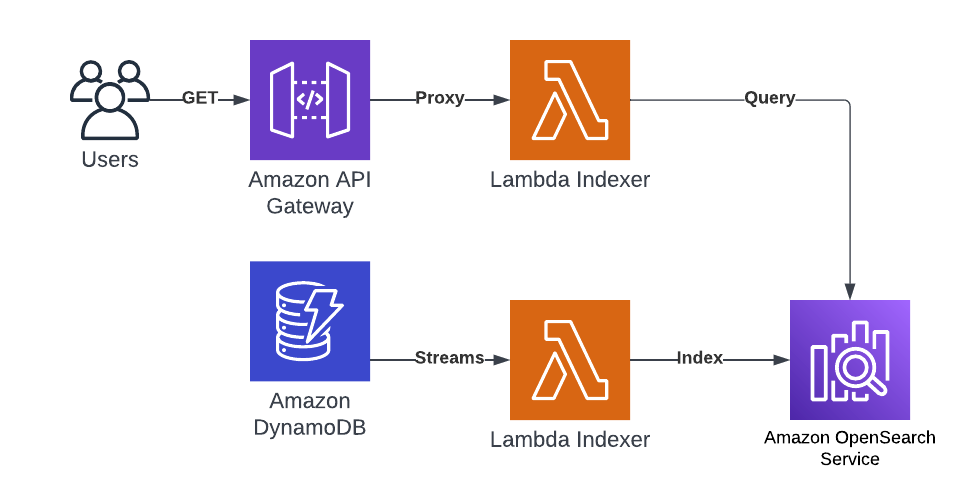
Data Source and Ingress
For this example we are going to have a product catalogue stored in DynamoDB. This will be configured with DynamoDB Streams so that any new, updated or deleted products will be captured. This stream will be sent into a Lambda function to call the OpenSearch APIs for indexing.
The Collection
Serverless is setup with a collection that has data access, networking and encryption policies attached to it. Once setup then you are given a dashboard URL for logging into the cluster.
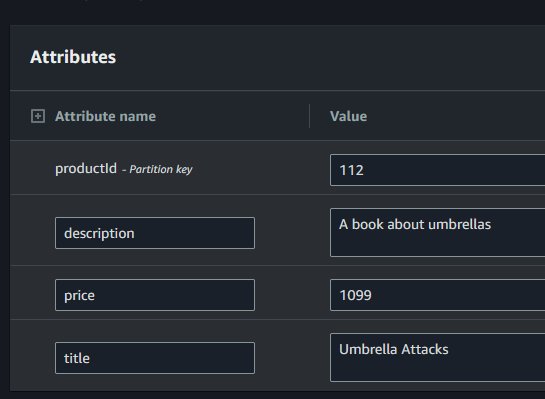
Data
DynamoDB is the source of data, I built nothing on top of this for managing the data as that is not part of my spike - but products can be added, updated and deleted directly there:
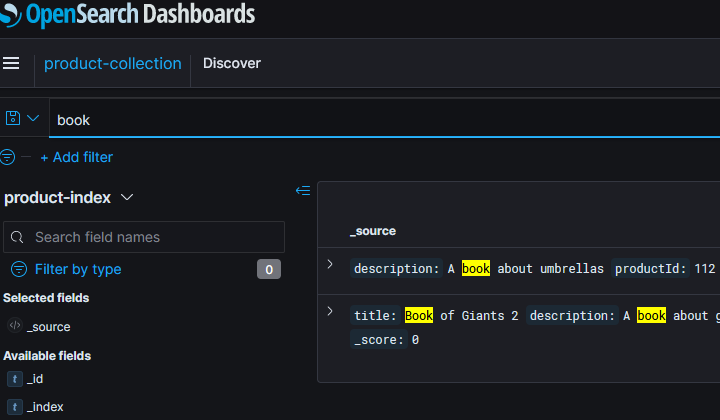
Searching
To allow searching then API Gateway uses a Lambda Proxy to call into the Search and return the results as JSON. I built a basic HTML page to show this in action:
Content Length and Signing Woes
The first major issue I had was getting the indexing working from Lambda. I decided to use the opensearch npm package but after setting that up with signing setup how OpenSearch suggest it failed with:
You can’t include Content-Length as a signed header, otherwise you’ll get an invalid signature error.
This turns out is a specific quirk of the Serverless offering and is in the documentation .
There are a few issues in the aws4 library around this problem too. This issue is made more annoying because tools like Postman use this header automatically in signing so it’s hard to manually test requests.
This then lead me down a path of pain because the code provided by AWS in the documentation for JavaScript/Node didn’t work, and I’m not 100% sure if it ever worked or it’s due to some version changes. The first issue is that the sample code has a workaround to remove content-length and add it back to the headers after signing, but the code sets the header to 0 and that means that is still gets added to the signed header but just as a 0.
After resolving that issue then I started to get Invalid signature, does not match errors even when the signing looked to be generating fine based on a lot of logging and trial and error.
I eventually came across an issue and linked commit
from Daniel Doubrovkine (From AWS) which showed that it was required to remove the body, sign and then re-add to get it to work - not just the content-length.
He then goes on to say :
I’m aking the serverless folks to make Sigv4 work the same way as for the managed service, so I expect the above to change before it’s officially launched out of preview.
That would have saved me a lot of time, but glad to see it’s a bug and not me doing it wrong! It is in preview so I understand these things happen, the downside of getting in there early.
Overall
When I first heard the headline of OpenSearch Serverless I immediately thought of a cluster that would scale to zero when its not indexing or searching. As I began looking into the product though, I realised this wasn’t the point of the service, it was actually being offered for the larger users to help them manage the clusters.
Whilst I can see this benefit being huge for certain customers, the pricing and minimum cost puts it out of reach for the majority of use-cases I personally have seen in the wild.
I’m very much looking forward to the improvements coming from General Availability that have been hinted at, and at that point I’ll dust this off and give it another go. For now, certainly check out the preview if you have larger clusters, but for hobby and small business projects then I wouldn’t delve into it until GA.
If you want to check out the code then please check it out on GitHub: https://github.com/makit/aws-opensearch-serverless