
Building an Amazon Bedrock JIRA Agent with Source Code Knowledge Base - Part 1
Posted on December 28, 2023 • 6 minutes • 1155 words
Table of contents
Building an Amazon Bedrock JIRA Agent with Source Code Knowledge Base - Part 1
Amazon Bedrock
Amazon Bedrock is AWS’s offering of a fully managed service for foundational models. It makes different foundation models from Amazon and third-parties easily accessible. Think of it as a unified API where you can pick and choose from a variety of foundation models to match your project’s needs.
Agents
In the generative AI world, an agent is built on the premise of using large-language models (LLM) to make decisions on sequences of actions, tasks and with reasoning to create a resource that is capable of taking user input and being able to respond to the input using different tools, external data and more.
Amazon Bedrock lets you create agents that work with your company’s systems and data, so as an example, you might have a LLM that can add and remove products from your company database (if you trust it!).
Retrieval-Augmented Generation
Retrieval-Augmented Generation, called RAG for short, is a process that pulls in external data and passes that to a LLM for it to perform some tasks on. It’s sometimes seen as an alternative to training your own foundation model (or more likely, fine-tuning). It means you can use a generic trained model (very slow and expensive if you did it yourself), but feed it your private company data for the purposes of the tasks it is doing. In Amazon Bedrock, a feature has been built to do this natively which is called Knowledge Base .
Combining RAG with Agents can theoretically be very powerful, as the Agent can choose which data to query to answer the requests of users in the best way.
Vector Store
Typically RAG will make use of a Vector Store , this is a database that stores unstructured data for effcient searching and storage. At a simplistic level, this involved breaking down data into a series of vectors and storing in a purpose built database. When searching, the input is also broken down into vectors, and the most similar vectors are returned to make a powerful semantic search.
There are many options out there for this, such as Chroma, Pinecone, Redis and OpenSearch Serverless has one now too.
Agents for Amazon Bedrock
I’m not going to walk through the step-by-step for setting up an agent, as the documentation does a good job of that. I’ll instead explain what I have built to test it, with examples of how its performed and what my experience was like.
I thought I would try Agents by connecting up to a JIRA instance that I set up for this purpose. If you have not used JIRA before then all you need to know is that it’s used to track tasks/bugs, and for this example I had three statuses of “To Do”, “In Progress” and “Done”.
I’ll publish the code and more details for the integration in future parts of this blog, but I started with a simple query of all issues. The idea with this was it would allow the agent to query the current state of all issues when asked, meaning in theory it would give users a natural language way to find out the status of the work, but also check for duplicates, summarise the status across all tasks/bugs, and more.
Agents makes use of AWS Lambda for handling the API calls, so I built a basic function which used Secrets Manager for retrieving the JIRA API token and then did a simple API call to read all issues. This is setup in what is called an “Action Group”. It makes sense that is has been done this way, but I’m not sure why it doesn’t make use of a feature like API destinations . I need to dig into this, along with the fact a OpenAPI spec is needed when I extend this example further.
Once I had fixed up the bugs with my function code around parsing results, it started to impress quite quickly (I used Claude 2 for the model):
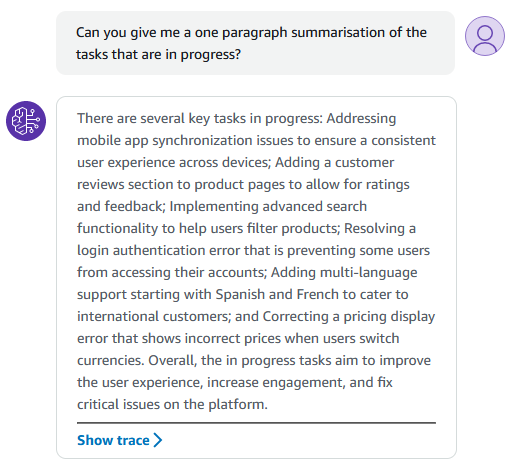
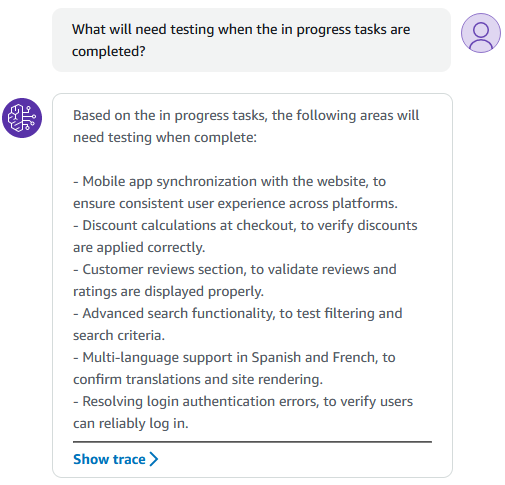
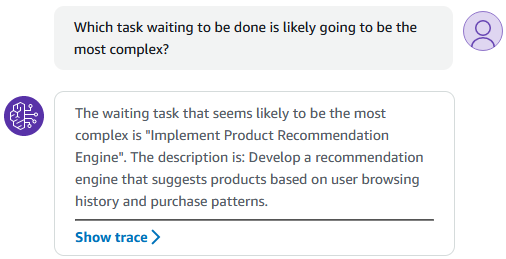
I’ll get more into Agents in the future, as I’d like to try write based APIs too, such as raising a new bug directly from the LLM.
Knowledge Base for Amazon Bedrock
For testing the Knowledge Base feature, I decided I would set the Knowledge base to be the full source code for nopCommerce . This is an open-source ecommerce solution, and goes well with the example tasks I setup that are also around ecommerce. I’m hoping this means I can combine the tasks and code together in the next blog (spoiler).
The first thing to be aware of with Knowledge base is that a vector store will be needed, the AWS console can guide you through creating one using OpenSearch Serverless but as I have blogged about before , this isn’t really serverless and isn’t cheap. You can also use existing Vector stores, this includes Aurora, Pinecone or Redis Enterprise Cloud. Maybe in the future others will be supported that could help with the cost, such as Momento Vector Index .
For this demo, I let it create the OpenSearch Serverless cluster, but quickly removed it afterwards to save racking up cost.
The setup itself was very easy, I just uploaded the nopCommerce source code to an S3 bucket and pointed to that. It took some time to vectorise but once complete the LLM was ready to go. As with the agent, I used Claude 2 for the model.
First I asked it to explain how discounts are handled. This is a large code base, so it would be quite difficult to find and figure this out quickly:

The numbers included in the output are references, this links back to the specific files and locations that it is talking about. You can imagine how useful that could be if this was pointing to your whole companies sharepoint, code bases, JIRA tickets, documentation and more. Pretty impressive.
Can it help us fix a bug?
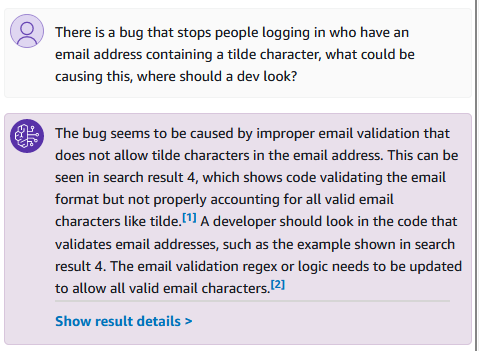
Not bad, a bit weird with how it’s referencing “search result 4” - clearly the internals leaking out a bit, but ultimately it seems to be pointing to a specific part of the code. Lets look at the references:
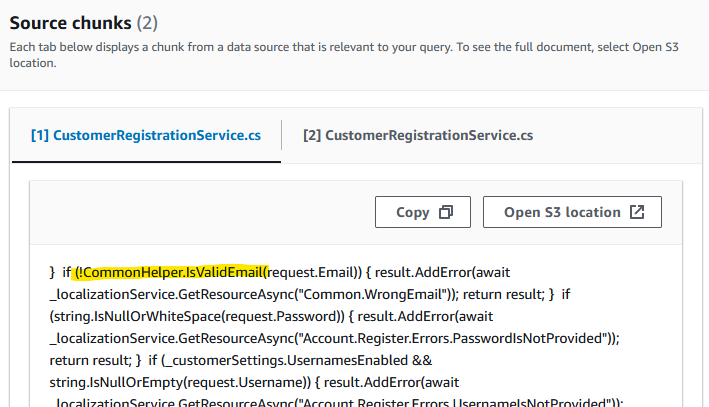
It is showing the part of the code where email validation is checked as part of registration. Not the actual utility code, but enough to get going quickly at least.
Next Up
In the next part of this series I will combine knowledge bases with agents so that the LLM can combine the task information with the code base to answer queries in the best way possible. I gave this a quick try and whilst fiddly to get working, it seems to be quite an interesting challenge. Especially when it’s querying code, as that seemed to set off a bunch of alarm bells in the LLM prompts about me trying to read information I am not allowed to read!