
Automated Dev Environment Per Branch with CDK
Posted on December 12, 2022 • 8 minutes • 1499 words
Table of contents
Infrastructure as Code (IaC) is an important part of Cloud Infrastructure, by utilizing flexible cloud resources, preferably serverless, then it opens up the possibility of a pipeline to create a full Developer environment per Branch, and then destroy it again after the Pull Request is merged.
DevOps is defined by AWS as:
the combination of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity: evolving and improving products at a faster pace than organizations using traditional software development and infrastructure management processes.
They also go on to say:
A fundamental principle of DevOps is to treat infrastructure the same way developers treat code.
Infrastructure as Code (IaC) is an incredibly important part of Cloud Infrastructure, as it goes hand-in-hand with the flexible nature of resource management that a cloud provider like AWS provides.
By treating Infrastructure in the same way as application code, it adds version control, reliability, clarity and ultimately the ability to recreate the infrastructure from scratch from a single well-defined source. This clearly has an impact on the velocity of delivering software.
The topic I’d like to discuss here is one huge benefit to having the infrastructure defined as code, and utilizing flexible cloud resources, preferably serverless, and that is the ability to create a full pre-production environment in minutes - and knowing it matches a version of production exactly.
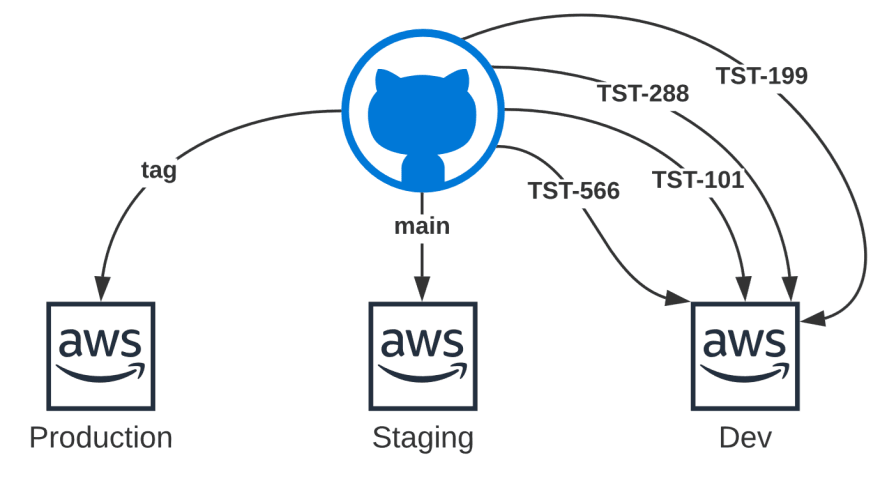
I don’t want to get into any specific branching strategy, so as to keep it high level a common issue is the fact that a lot of work goes on in the Dev environment, but less so on the other environments, this environment could be local, but that becomes harder with distributed cloud-native solutions.
Sequence
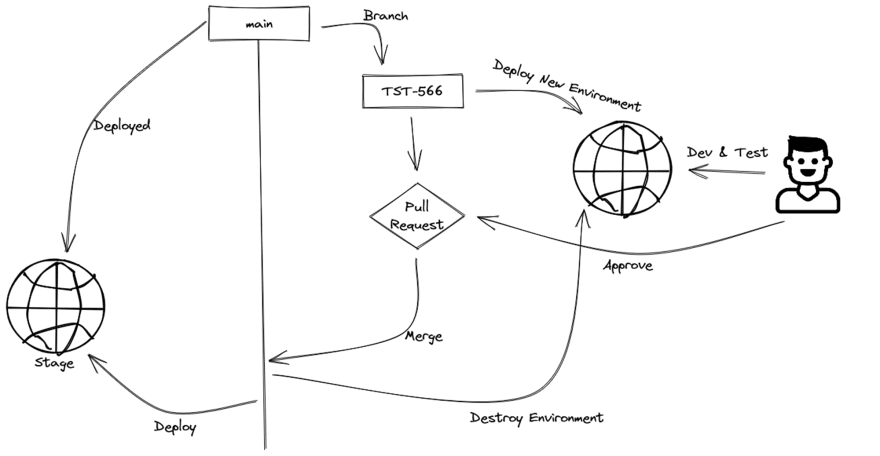
This shows a simplistic sequence of what I will delve into, we have a main branch here that is deployed to a stage environment (ignoring production for now).
A branch is created from there with a ticket ID for development, that that will cause CI to deploy a whole new dev environment that can be used for development and testing.
The PR can then be approved and merged, which will cause the environment to be destroyed and the Stage environment to be refreshed.
These environments are created and used only for each branch, and only one developer is active on that branch. They are continuously deployed so they don’t get stale, and it forces good practices of using IaC because anything done manually in the Console will be lost on the next deployment.
System Overview
The following is the system being used to demonstrate this:
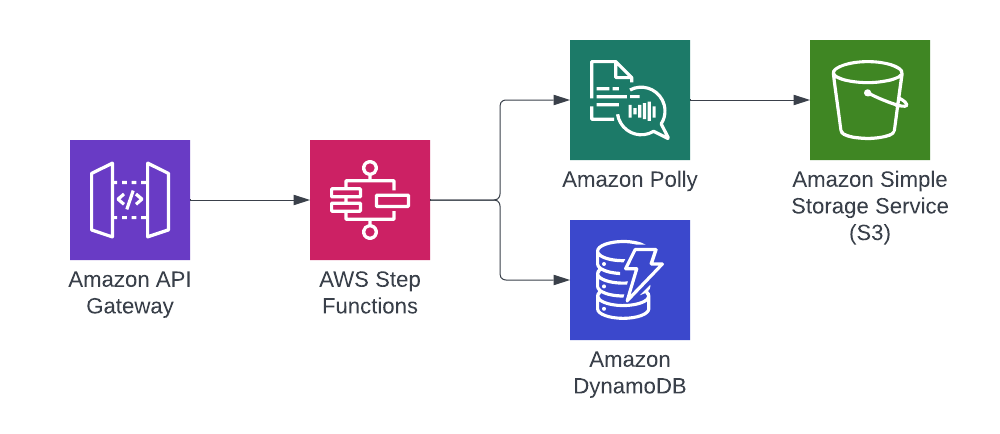
The application is broken down into two stacks, which is a Stateless stack and a Stateful stack. This breakdown is a useful pattern to isolate the resources which carry more risk, versus those without. An example of this could be that if the application renames some IDs and the stack needs deleting and recreating, if this happened in a stack with stateful and stateless resources (S3 bucket and a lambda for example) then it could mean losing all the data.
CDK
AWS Cloud Development Kit is a software development framework used to model and provision your cloud application resources with different programming languages. This means networks, servers, load balancers, etc, can be defined with code, and then deployed to your cloud account with a single command.
CDK is used for this example, but we have used CloudFormation and Terraform to do similar processes - they just rely a bit more on CI scripts.
Steps to Achieve in CDK
Injecting Branch Name
The branch name needs to be read in, with it being TypeScript then it could be read dynamically by running git processes or via NPM packages - but this is a clean and safe way to do this. A context variable is used for this:
const branch = this.node.tryGetContext('branch');
if (!branch) {
throw new Error('Branch is required!');
}
Common Shared Stacks
If there are resources which need to be shared (such as a VPC) then a simple pattern can be used to check the branch name so they are only deployed for Trunk. If these resources are needed across stacks then they need to be exported and imported - rather than a variable output from one stack and then used in another (CDK then does an export/import for you). See the Notification Topic for an example.
if (branch.toLowerCase() === TRUNK_BRANCH_NAME)
{
new NotificationStack(this, 'CommonNotificationStack');
}
Dynamo Stack Names
The most important change to allow the stacks to be created per branch is to dynamically name the stacks:
const statefulStack = new StatefulStack(this, `${branch}-GenSpeechStatefulStack`);
Destroy Stateful Resources
For stateful resources, like S3 and Databases for example, then it’s important to fully destroy them when the branches are merged. By default they will be set to Retain. This should not happen for the Trunk branch though, as that could be dangerous for production:
const removalPolicy = props.destroyOnRemove
? cdk.RemovalPolicy.DESTROY
: cdk.RemovalPolicy.RETAIN;
this.generatedMp3Bucket = new s3.Bucket(this, "GeneratedMp3Bucket", {
removalPolicy,
// This needs enabling too, which will create a Lambda to wipe the bucket before deletion
autoDeleteObjects: props.destroyOnRemove,
});
this.auditTable = new dynamodb.Table(this, 'AuditTable', {
partitionKey: { name: 'day', type: dynamodb.AttributeType.STRING },
sortKey: { name: 'taskId', type: dynamodb.AttributeType.STRING },
removalPolicy,
});
Naming Resources
A lot of the resources will be named automatically by CDK using a prefix from the stack name, and then a hash. This means the majority of the resources will have the branch name in the resource name for easy navigation/searching. The resources that don’t do this will be an issue (Step Functions, API Gateway, etc) - and could even clash completely, such as API Gateway which uses just the ID as the name. To ensure all resources are uniquely named, and have the branch name in them, then for these resources the branch name should be passed into the stack and a property set as appropriate:
return new stepfunctions.StateMachine(this, `PhraseSynthesiser`, {
// Set the name to match the branch - this is optional but helpful
stateMachineName: `PhraseSynthesiser-${props.branch}`,
definition: stateMachineDefinition,
stateMachineType: stepfunctions.StateMachineType.EXPRESS,
});
Adding Tags
To help finding resources, as well as reporting on cost per branch, then it’s suggested to tag the stacks with the branch name so that all taggable resources are tagged too.
cdk.Tags.of(statefulStack).add('Branch', branch);
cdk.Tags.of(statelessStack).add('Branch', branch);
Gotchas
- Branch Names - Branch names need to work with AWS limits, such as SQS having a maximum length of 60 characters – length and character checks should be done in the CDK code and/or in CI. Casing can be an issue as well, such as S3 bucket names being in lowercase. Therefore Git will allow separate branches differing only by case, but AWS would clash for some resources.
- Resource Names - Resource names can be a problem for debugging, for example, if you have 10 branches with 20 lambdas in each branch then it can be a problem to find the resources quickly. Tagging is recommended for all resources by tagging the stacks, custom naming can help too by making sure all resources contain the branch name.
- Clean-Up - Cleaning up needs to be thorough, you don’t want to leave buckets around by accident and a year later it’s potentially mayhem. You need to ensure alerting takes place for any failures in the destroy CI scripts to allow them to be manual resolved if needed. I have spent time manually deleting a lot of resources due to not doing this correctly. It’s also important to ensure the resources are configured correctly to allow CloudFormation/Terraform/CDK to delete them fully (such as S3 buckets).
- Resource Limits - AWS resource limits should be checked and monitored, if 200 lambdas are deployed for an app then it adds up fast if there is a lot of concurrent development. Things like Security Groups might be done behind the scenes in CDK so it’s important to go through what’s actually deployed in CloudFormation and do the maths to ensure all types of resource are taken care of.
- Cost - Cost is a fairly obvious one if using resources that cost money for just existing. I am predominantly serverless so scale-to-zero means 100 or 1000 lambdas doesn’t matter. If you have resources such as EC2s or NAT gateways then it can add up quickly, one way is to split these out into common shared stacks that are not deployed per branch. It might be that you can’t do this and so you can try to set limits to the number of branches and length of time they can exist. Alternatively EventBridge schedules can be used for shutting down resources/destroying stacks after certain time limits.
- Awareness - All developers using the CI system need to be aware that this happens, they might create lots of branches without knowing that it’s deploying a full environment each time – you might have seen people with TST-123A, TST-123B, TST-123C etc and they don’t realise it’s spawning all these environments.
More Info
Please take a look at the GitHub Repo for more information and to try it out.